R中一些包及函数,由于其实用便捷性,总会不经意间改变人们的代码习惯,比如pivot(旋转)数据
最开始的时候,我们会在R的一些教程书中看到有长/宽数据的转化,其实就是pivot,为了将数据结构满足一些函数以及软件的输入需求,或者为了后续编程方便
- 在翻一些早些年的教程中会看到,有人会建议你使用
reshape2::melt()和reshape2::cast()函数,我也是如此。。。 - 后来在一些书中会推荐你用
tidyr::spread()和tidyr::gather()函数,自从用了这个后,我就放弃使用melt()了 - 自从我了解到
spread()和gather()函数被重塑,已被tidyr::pivot_wider()和tidyr::pivot_longer()替换后(前者的help文档中已经开始推荐使用后者了),我发现后者果然真好用。。。
从上可看出,一些函数的出现会改变数据清理中pivot实现代码的编程习惯。。。
以下笔记主要参考资料:Pivoting data from columns to rows (and back!) in the tidyverse
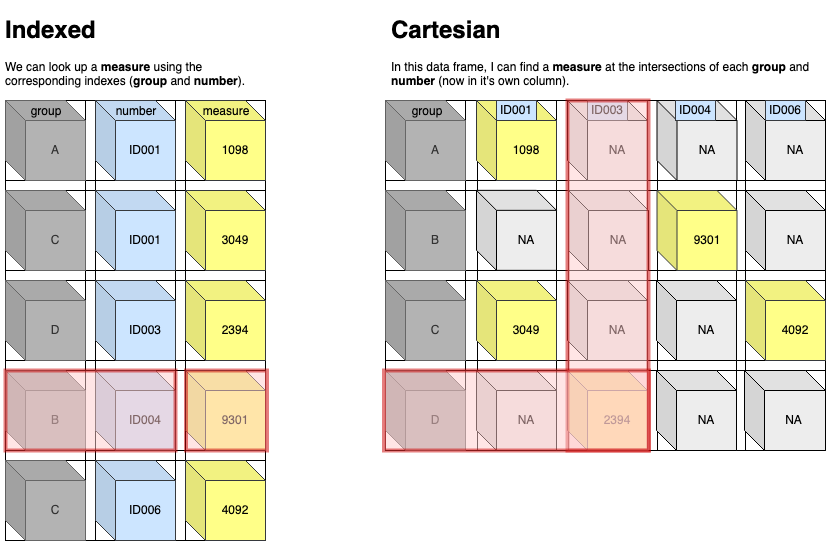
首先需要先理解下什么是“长数据”和“宽数据”,前者对应上述文章中的Indexed data,而后者对应Cartesian data,如下图所示:
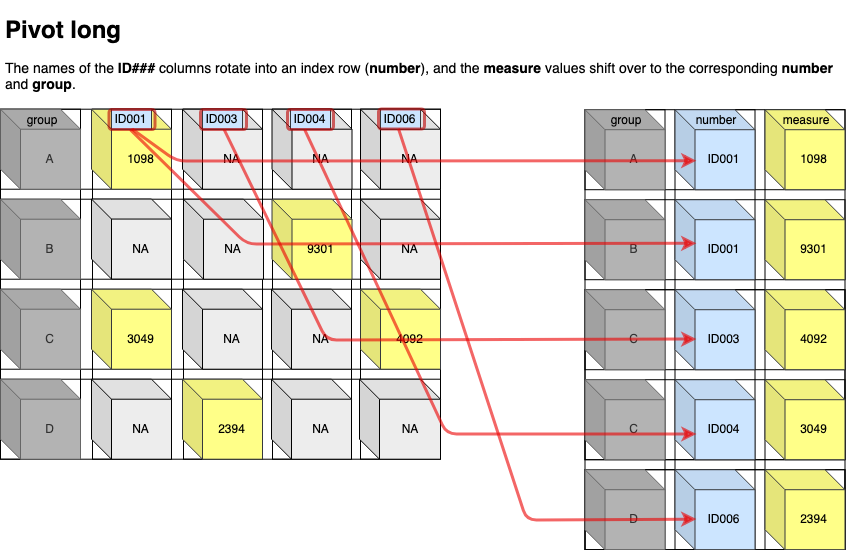
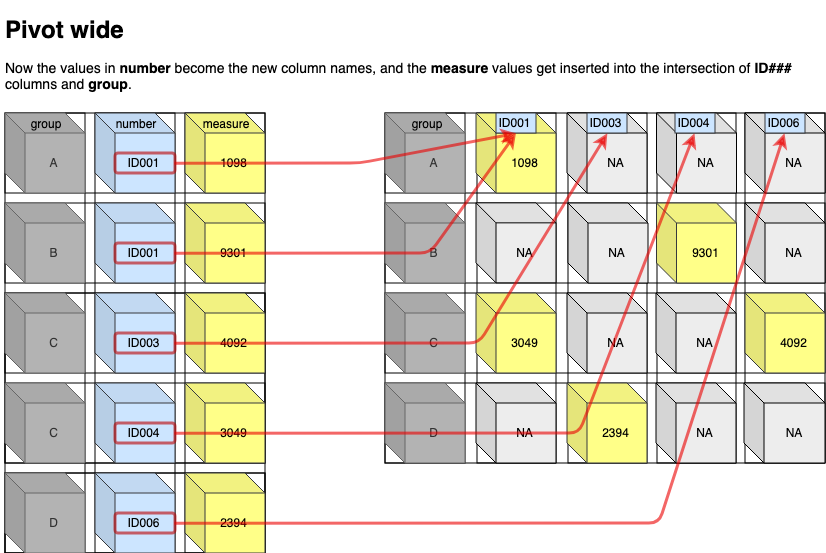
对于pivot概念不太清楚的,可以参照上述参考资料中的下述图片,便于理解:
接着以测试数据来实际使用下,先加载文档中提到的数据集
download.file(url = "https://github.com/mjfrigaard/storybench-posts/raw/master/data/2019-08-03-tidyr-pivot-post-data.RData",
destfile = "./tidyr-pivot-post-data.RData", mode = "wb")
base::load("./tidyr-pivot-post-data.RData")对于spread和gather用法在此就不做比较了,主要看下pivot_longer和pivot_wider
比如pivot_longer将宽数据变成长数据,cols参数可以用一些tidyselect的方法,names_to和values_to分别对应类别和对应的值,names_prefix主要用于删除类别中一些重复的前缀文字,values_drop_na则去除NA
LomaWideSmall %>%
tidyr::pivot_longer(
cols = starts_with("fight"),
names_to = "fight_no",
values_to = "result",
names_prefix = "fight_",
values_drop_na = TRUE)
# A tibble: 14 x 4
opponent date fight_no result
<chr> <date> <chr> <chr>
1 José Ramírez 2013-10-12 1 Win
2 Orlando Salido 2014-03-01 2 Loss
3 Gary Russell Jr. 2014-06-21 3 Win
4 Chonlatarn Piriyapinyo 2014-11-22 4 Win
5 Gamalier Rodríguez 2015-05-02 5 Win
6 Romulo Koasicha 2015-11-07 6 Win
7 Román Martínez 2016-06-11 7 Win
8 Nicholas Walters 2016-11-26 8 Win
9 Jason Sosa 2017-04-08 9 Win
10 Miguel Marriaga 2017-08-05 10 Win
11 Guillermo Rigondeaux 2017-12-09 11 Win
12 Jorge Linares 2018-05-12 12 Win
13 José Pedraza 2018-12-08 13 Win
14 Anthony Crolla 2019-04-12 14 Win pivot_wider将长数据变成宽数据,比如将上述长数据再变回款数据,id_cols作为保留的索引,names_*此类参数是对于将要转化的列的处理,value_*此类参数则是对应转化后的行列对应的值
LomaWideSmall %>%
tidyr::pivot_longer(
cols = starts_with("fight"),
names_to = "fight_no",
values_to = "result",
names_prefix = "fight_",
values_drop_na = TRUE) %>%
tidyr::pivot_wider(
id_cols = c("opponent", "date"),
names_from = fight_no,
names_prefix = "fight",
names_sep = "_",
values_from = result,
values_fill = list(result = NA)
)其中values_fill可以对不同变量进行设置(当values_from有多个值时),下述例子相当于看rounds-type和time-type的组合下对应的宽数据
LomaFights %>%
dplyr::filter(result == "Win") %>%
pivot_wider(names_from = c(type),
values_from = c(rounds, time),
values_fill = list(rounds = "", time = "-"))详细说明可参考英文原文
本文出自于http://www.bioinfo-scrounger.com转载请注明出处