不知不觉,写这个博客一年了,也可以说刚好一年整
最初只是临时起意,将博客作为一个学习过程的督促者,在阿里云上买了个服务器,用wordpress尝试搭建了博客,那时感觉还不错,就开始在博客记录自己的笔记。当时也不知道自己能坚持多久,但是有一点还是明白的,只要每天都学习一点,这个博客就会一直更新下去,就这样写了一年 虽然每篇文章的质量参差不齐,但代表了我从初学者一步步走过来的足迹,是这一过程的见证者。从内容上讲,似乎在不同方向都有涉及,主要是为了明白其是什么,其用于什么,其能给予什么结果等问题,但都浮于表面并没有深入的研究,这需要我之后再进一步的学习。从数量上讲,我还是初步完成了当初所定的目标:平均每周两篇,后来写着写着发现,能将自己所学的,记录并展示出来也是件很有意思的事情;有些知识点,当初看完后觉得自己懂了,但当自己写(表达)出来时,才发现自己还是有所欠缺
这两天心血来潮,打算用爬虫的方式,来扒一扒我的博客主页,来看看我这一年来写了些什么,准备使用rvest包,因为这个包使用非常简单!!!如果需要爬虫大型网页的话,还是Python比较适合,但是想快速入门,R则是不错选择
所需基础:R语言以及CSS/HTML,后者只要略懂一些即可,也可以用selectorgadget谷歌插件来帮忙(主要用于获取标签信息)
对于rvest包的主要函数,可以参照R:rvest包总结,写的非常详细;而我只用了其中几个函数即可,并没有深入研究,等以后有需要的时候再来翻翻
这里以一个例子来说明下具体过程,比如获取我博客首页的文章名称
首先是获取网页,用
read_html读取网页library(rvest) url <- "http://www.bioinfo-scrounger.com" webpage <- read_html(url)接着要寻找文章名称的元素/CSS标签,这里最简单的是用
selectorgadget谷歌插件,但是我们也要学会自己来寻找所需信息,比如从网页的源代码中可以发现,文章名称是包在元素\里面的,而元素\则是在类为entry-header的元素\下,所以我们可以用
html_nodes来获取这一节点的信息,html_text转化为文本html <- html_nodes(webpage, '.entry-title a') paper <- html_text(html) > paper [1] "R学习笔记 作图Tips" [2] "修改CSS自定义wordpress主题(伪)" [3] "用AnnotationHub获取非模式物种注释信息" [4] "R作图 ggplot2图片的布局排版" [5] "使用Shiny快速开发web程序" [6] "用XML包解析uniprot的API网页" [7] "Bioconductor的质谱蛋白组学数据分析" [8] "Differential expression in proteomics" [9] "用亚马逊的AWS来搭梯子" [10] "Bioinformatics for Proteomics Data"
其他需要抓取的内容也可以做类似的处理,下面是我爬虫整个博客的代码,抓取的信息有:文章标题,分类信息,月份,日以及文章链接
library(rvest)
library(dplyr)
blog_info <- data.frame()
##因为每页只有10篇文章,所以根据URL规则循环抓取信息
for(i in 1:10){
url <- paste0("http://www.bioinfo-scrounger.com/page/", i)
webpage <- read_html(url)
##抓取文章名称
paper <- html_nodes(webpage, 'header.entry-header a') %>% html_text()
##抓取文章分类信息
class <- html_nodes(webpage, 'span.entry-categories a') %>% html_text(trim = TRUE)
##抓取文章月份/日(月份以年-月表示)
date <- html_nodes(webpage, "span.posted-on a") %>% html_text(trim = TRUE)
date_month <- unlist(lapply(date, function(x){
tmp <- strsplit(x, " ")[[1]]
paste(tmp[3], tmp[1], sep = "-")
}))
date_day <- unlist(lapply(date, function(x){
tmp <- strsplit(x, " ")[[1]][2]
sub(",", "", tmp)
}))
##抓取文章链接
href <- html_nodes(webpage, 'header.entry-header a') %>% html_attr("href")
info <- data.frame(Paper=paper, Class=class, Month=date_month, Day=date_day, URL=href, stringsAsFactors = F)
blog_info <- rbind(blog_info, info)
}
> head(blog_info)
Paper Class Month Day URL
1 R学习笔记 作图Tips R 2018-三月 21 http://www.bioinfo-scrounger.com/archives/520
2 修改CSS自定义wordpress主题(伪) 杂货笔记 2018-三月 19 http://www.bioinfo-scrounger.com/archives/516
3 用AnnotationHub获取非模式物种注释信息 Basic 2018-三月 18 http://www.bioinfo-scrounger.com/archives/512
4 R作图 ggplot2图片的布局排版 R 2018-三月 15 http://www.bioinfo-scrounger.com/archives/509
5 使用Shiny快速开发web程序 R 2018-三月 11 http://www.bioinfo-scrounger.com/archives/506
6 用XML包解析uniprot的API网页 R 2018-三月 07 http://www.bioinfo-scrounger.com/archives/504最后将上述结果可视化一下,也就是做个图,看看每月/每日文章数目
library(Rmisc)
library(ggplot2)
df_month <- as.data.frame(table(blog_info$Month))
names(df_month) <- c("Month", "Num")
df_month$Month <- factor(df_month$Month, levels = unique(rev(blog_info$Month)))
p1 <- ggplot(df, aes(x = Month, y = Num)) +
geom_bar(stat = "identity", fill = 'steelblue', width = 0.5) +
theme_cleveland() +
theme(
axis.text.x = element_text(angle = 90)
)
p1
df_day <- as.data.frame(table(blog_info$Day))
names(df_day) <- c("Day", "Num")
p2 <- ggplot(df_day, aes(x = Day, y = Num)) +
geom_point(size = 5, shape = 21, fill = "steelblue") +
theme_cleveland()
p2
list_p <- list(p1, p2)
multiplot(plotlist = list_p)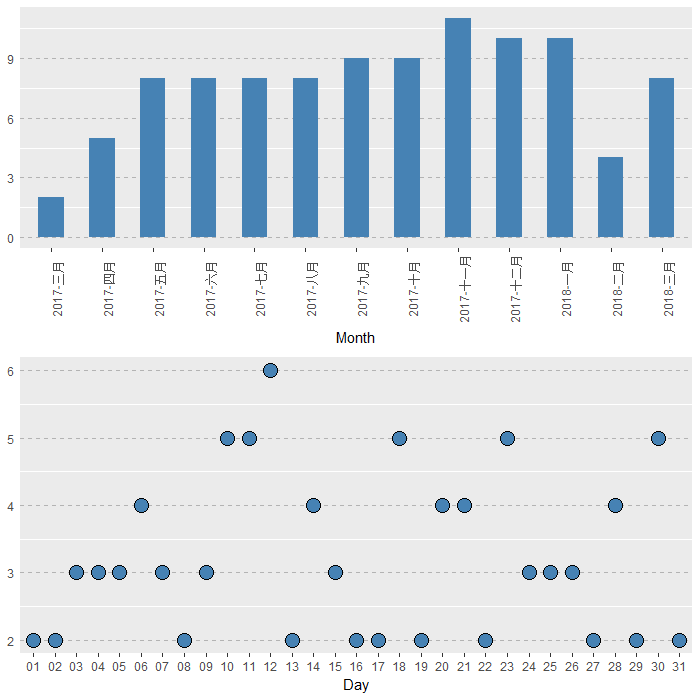
从图中可看出,去年11月写的博文数目最多,而其中每个月中的12号写的博文最多,相当于一年12个月里,有一半时候都是在12号写的博文。。。
在以雷达图看下我的不同分类的统计结果,用的是ggplot2的插件ggradar,安装需要借助devtools,则library(devtools),install_github("ricardo-bion/ggradar"),从图中可看出,转录组和R语言的比例较大;接下来则是基础、基因组和芯片,编程语言中Perl相比R低了不少(虽然我最先学习的是Perl......);统计分析最少,这也是之后主要学习的部分
data_class <- table(blog_info$Class[blog_info$Class != "杂货笔记"]) %>% as.matrix()
data_class <- apply(data_class, 2, function(x){
x/sum(data_class[,1])
})
data_class <- data.frame("", t(data_class))
ggradar(data_class, grid.mid = 0.125, grid.max = 0.25, grid.label.size = 5,
axis.label.size = 5, group.point.size = 5)
综上所述,以上爬虫加统计可视化纯属是娱乐娱乐。。。
本文出自于http://www.bioinfo-scrounger.com转载请注明出处